Abstract
Applications of computer vision on natural images have seen great success recently, yet there are few approaches dealing with visual illustrations. We propose a collection of computer vision applications for parsing genetic models. Genetic models are a type of visual illustration often used in the biological sciences literature, used to demonstrate how a discovery fits into what is already known about a biological system. A system that determines the interactions present in a genetic model can be valuable to researchers studying such interactions. The proposed system contains three parts. First, a triplet network decides whether or not a figure is a genetic model. Second, the object detection network YOLOv5 is trained to locate regions of interest within genetic models using various deep learning training techniques. Lastly, we propose an algorithm that infers the relationships between the pairs of genes or textual features present in the genetic model. Components of this system power the search functionality of the Bio-Analytic Resource for Plant Biology tool at the University of Toronto.
Overview
Our proposed method, shown below, constructs textual descriptions from a genetic model in three steps. First, a triplet classification network is trained on our synthetic dataset GeneNetSyn to classify whether or not an image is a genetic model. Next, a YOLOv5 model identifies the constituent blocks within genetic models: genes (geometric shapes enclosing the names of genes or proteins) and the activation and inhibition lines between these nodes.
Building the labeled dataset for the first classification step is relatively easy: it simply requires images of genetic models and other publication figures paired with a binary label. The region detection model in the second step, however, requires richly annotated datasets that are burdensome to acquire, so the YOLOv5 model, initially trained on natural image datasets, is fine-tuned on synthetic data using domain adaptation and transfer learning. Before the third step, the system leverages the Google OCR API to extract textual elements, often genes and proteins, presented in a convenient scheme to index the genetic model within the University of Toronto's BAR. Lastly, an activation and inhibition line analysis system extracts textual descriptions of the form "Gene A inhibits Gene B."
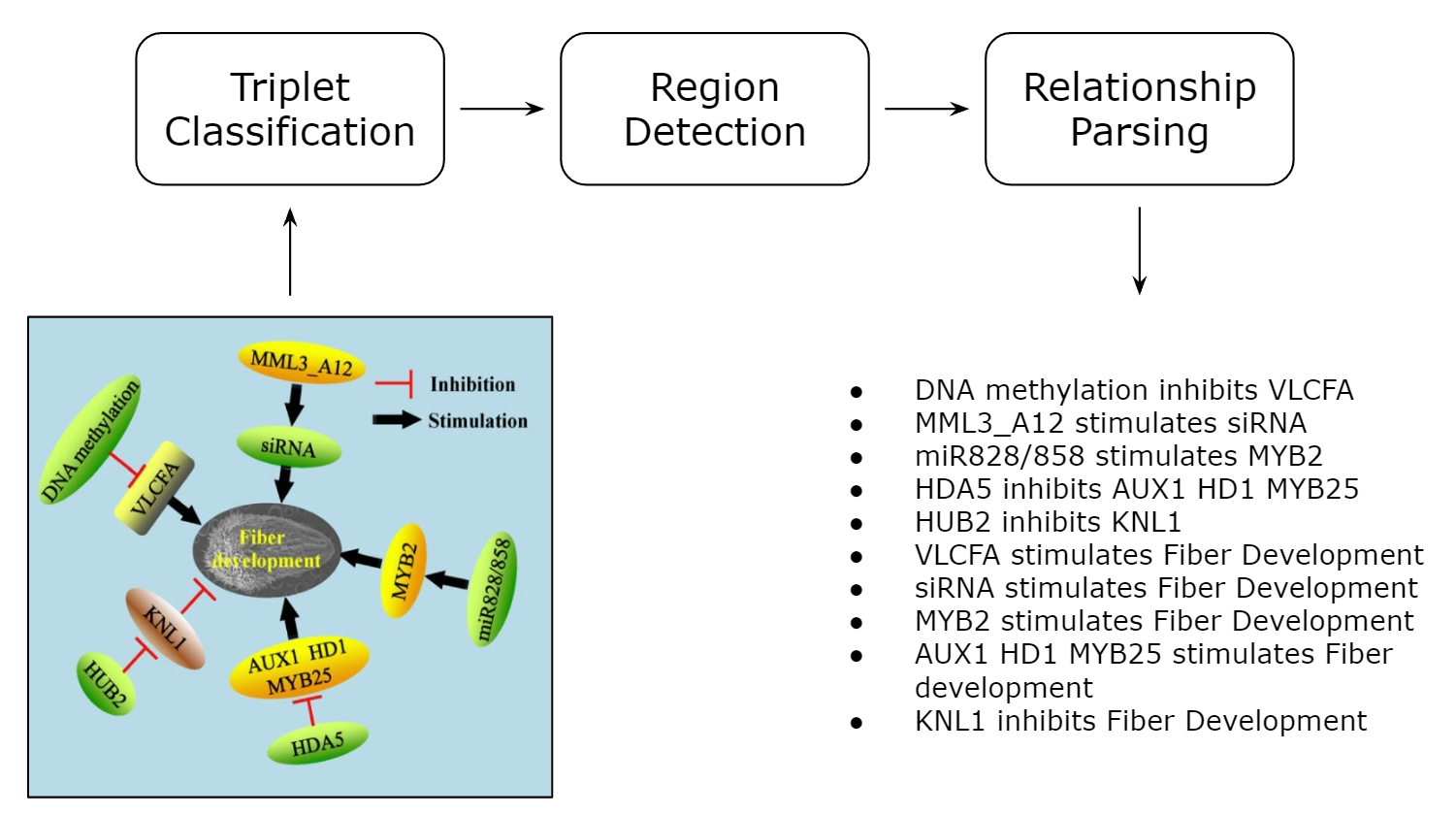
Datasets
We introduce both real and synthetic genetic model datasets, titled GeneNet and GeneNetSyn respectively. Training a deep neural network is a data-dependent task, so we require large collections of data supplemented by richly annotated ground truth.
GeneNet
There are currently no publicly available publication-figure datasets in the scope of plant biology. To train a computer vision system for diagram parsing, we require a richly annotated dataset of both publication figures and genetic models. The GeneNet collection offers ground truth for genetic model classification, region detection, and diagram parsing, opening a new avenue for computer vision applications in genetic model analysis.
GeneNetSyn
We propose a collection of synthetic datasets that iteratively increase in visual complexity. Their goal is to mimic the interaction of genes through the relationships present in the real genetic models of GeneNet.
Approach
Genetic Model Classification
To decide whether a given publication figure is a genetic model, we use a triplet classification network. A triplet network takes three input images to decide whether the image of interest (the anchor) is more similar to the positive or the negative class from the dataset. For each item passed to the network, the data is divided into three sub-batches: the anchor, a positive class example, and a negative class example.
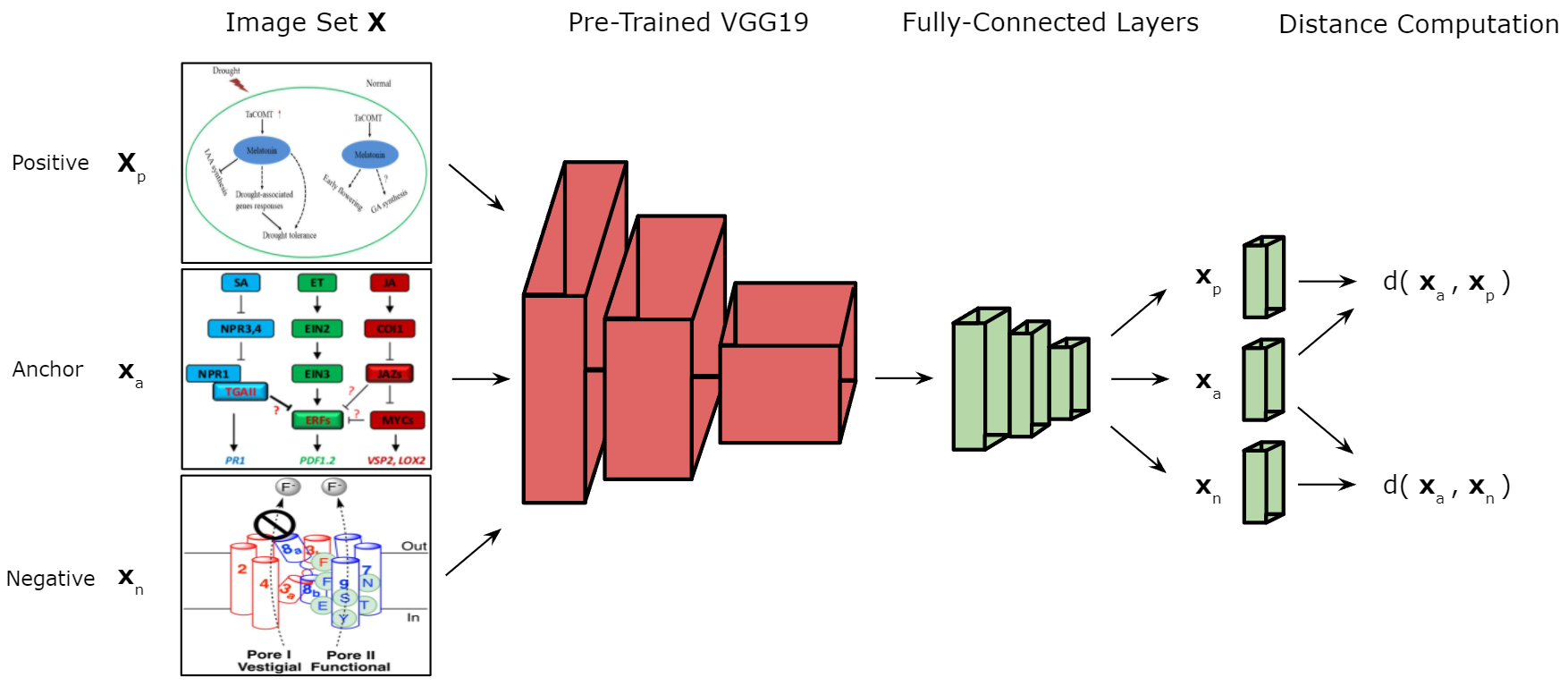
Region Detection
We employ two learning techniques to transfer weights from Microsoft COCO to the synthetic genetic models in GeneNetSyn. First, instance-based mapping transfer learning tunes the weights from the source domain to our target domain. Second, we introduce domain adaptation to the region detection training to smooth the transition from natural-image weights to genetic models. Although the region detection networks are trained on GeneNetSyn, we add real genetic models from GeneNet so the synthetic-to-real transition has less impact on performance.
Parsing Relationships
To parse the entities associated with a relationship, we use an active contour model. This approach uses no machine learning inference or prediction. The goal is to generate sets of triplets representing the entity-relationship-entity structures found within a given diagram, and the methodology works for both GeneNet and GeneNetSyn diagrams. The main difference is how text within features is collected: for GeneNetSyn we assume text-to-bounding-box associations are known, while for real genetic models the text is located using optical character recognition. The approach has three steps: initialization, relationship pairing, and entity-relationship-entity extraction.